Learning to count with RNNs
Recurrent neural nets. Today RNNs are doing amazing tasks. They achieve the state-of-the-art in many applications. I always wondered how they work. But now after some reading and some coding, they appear super simple. In this post, we will implement a vanilla RNN in tensorflow and also gain some insights on its working. If you are not very sure about RNNs, this is an excellent blog by Andrej Karpathy. Also, this video lecture is awesome.
1,2,3,4… I decided to build a simple recurrent net. But what do we do with it? what do we learn? RNNs are good at learning sequence. Hmmm, what is one of the first sequences which a child learn? Yes! the numbers. One, two, three… . So is it possible that we teach RNN the counting from 1 to 100 and then later it learns to produce the subsequent numbers 101,102,103… . looks interesting.
How do humans approach this problem?
This problem is essentially the same as learning to add one to a given number. How we do this? Find 1476233999 + 1. We start from the very right. We know 9 + 1 = 10, so the result would end in a 0, we pass the carry to the left digit. so again it’s a 9 + 1 and so on. (the answer is 1476234000 :p)
Why RNNs? This problem can be very easily solved using a simple linear regressor y = a*x + b put a=1 and b=1 and its done! so why RNN? The working of the RNN resembles very closely to how we solve the problem. It learns 2 comes after 1, 3 after 2 and so on. It also learns to remember a carry and use it for further processing. It’s really great to see how it learns all these.
The model We will use a single layered vanilla RNN cell. Given a number, we will train it to predict the next number. In this problem, we can just generate the dataset on our own and it would be free from any noise but this is not the general case. In the beginning of the post, I wrote about training the network on 1 - 100 and then predicting the further numbers. But in practice 100 examples are too few for an RNN to learn anything good. I used a dataset of 9K training and 1K validation examples of numbers up to 10 digit long.
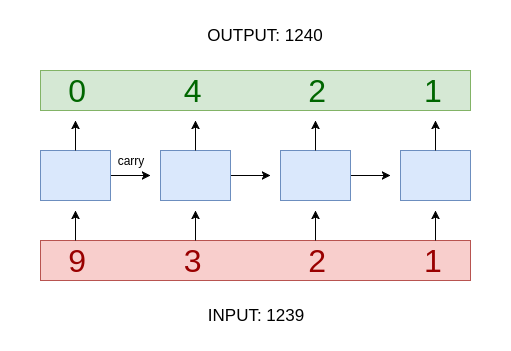
We break the input number into a sequence of digit and then convert those digits to one hot encoding. Since the calculations had to start from the very right of the number, we can simply invert the input sequence and pass it to the RNN.
Code is available at this github gist
# data placeholders
x_batch = tf.placeholder(tf.float32, [None,T,D], name='x_batch')
y_batch = tf.placeholder(tf.int64, [None,T], name='y_batch')
N = tf.shape(x_batch)[0]
# initial state for RNN
hidden_state = tf.zeros([N,H], dtype=tf.float32)
# weights and biases for the fully connected layer to get class scores
W = tf.Variable(np.random.rand(H,C),dtype=tf.float32)
b = tf.Variable(np.zeros((1,C)), dtype=tf.float32)
# create a RNN cell
cell = tf.contrib.rnn.BasicRNNCell(H)
# run the cell over the input
# current_state is the final hidden state of the RNN
# states_series contains the hidden states over all the time steps
states_series, current_state = tf.nn.dynamic_rnn(cell, x_batch, initial_state=hidden_state)
states_series = tf.reshape(states_series, [-1, H])
# class scores
logits = tf.matmul(states_series, W) + b
logits = tf.reshape(logits, [-1,T,C])
# training loss
losses = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, labels=y_batch)
prob = tf.nn.softmax(logits)
# predicted output
pred = tf.argmax(prob, axis=-1, name='pred')
# accuracy
acc = tf.contrib.metrics.accuracy(pred, y_batch)
total_loss = tf.reduce_mean(losses)
train_step = tf.train.AdagradOptimizer(1).minimize(total_loss)
Result Our network reach 100% accuracy on both training and validation set after 3-4 epochs. The model was trained with numbers up to 10 digit long. But I have randomly tested it with numbers up to 20 digit long, and it worked perfectly well. so I guess we achieved our target :-)
Is it 100% accurate? No. It works fine for numbers up to 23-25 digit long. But we can’t be sure after that. More specifically it fails when the number contains over 25 ‘9’s at the end. In that case, it has to pass the carry continuously for over 25 positions. But the network does not remember carry for this longer and eventually fails.
Why the RNN fails to remember carry? I don’t have a good answer here. May be this is because of vanishing activations. The network gets the same input again and again and is multiplied by the same weight matrices. So repeated multiplication of same matrix could have resulted in some damping effect on the value of carry. Let me know what do you think about this in the comments.
Observations I tried LSTMs on this one but they give similar results. I also experimented with location and content based attention mechanisms but they don’t give good results. These approaches work good for sequences in the training length but fail there after. Also they suffer from the same carry problem.
Conclusions RNNs are very simple yet very powerful models. I think that RNNs augmented with some fancy external memory architecture could yield amazing results. In search for that one.